Metadata Management
Metadata is “data about data”: everything that helps describing and better understanding data can be considered as such.
1. Introduction
Metadata Management is a very specific subfield of Data Management that revolves around the notion of metadata. Managing metadata may be even more important than managing data, and it is absolutely necessary for a professional and high level practice of Data Management. Metadata gives various context elements about data, and managing it takes the management of data to the next level.
Metadata appear at the same time as data are created. For example, information about databases, transformation tools, operations and modifications applied on data, business owner of the data, physical systems that host data. Information about all these elements constitute metadata, and as such, should be managed properly to extract their inner value.
Metadata permit to contextualize data thanks to the famous 5 ‘W’ questions : Who? What? When? Where? Why?
It is really important to have answers to these questions, so as to better use considered data in their proper context. Data without a solid Metadata Management system and process can make them unreliable, thus ignored by data consumers or business users.
Metadata also helps to have a better understanding of a company/context heritage, leading to a more efficient use of data. This is used to document business, data, processes and more generally everything that revolves around business that has a link with data. Business users can ask questions about data (definitions, meaning, origin, use, etc.) to the Metadata Management system, to better understand their context and the path data went through until their final use.
Metadata Management has a very simple goal: increase trust in data. Generated data in a complex environment such as a company or a large system can quickly become messy, with lots of silos and incoherence. Without metadata, it is very easy for data consumers to get lost and to not understand data they have in front of them. This can cause many additional costs on projects and data initiatives, as people lose time understanding data context, glossary, and origin. In the worst case, consumers could ignore these data because of a lack of trust.
When we talk about Metadata Management, there are a lot of terms, specificities, tools, methodologies that come in mind. Among those notions, a few of them appear regularly in every article or documentation references. For example, defining metadata, governance models and strategy elements that come along metadata information articles is a very important step to begin with. Talking about architectures and data models that serve Metadata Management is also crucial to give concrete examples. Finally, everything that revolves around Data Catalogs and according metrics are definitely essential terms and notions that should accompany discussions about this field.
2. Metadata
Metadata can be seen as concrete and complementary information, that resides aside original data. It can be of various forms, as it is data itself. However, metadata in its purest form is simply “data about data”. Metadata can be characterised in many types, depending on the semantics it holds and the type of data it describes. We generally find three types of metadata: Business, Technical and Operational.
Business metadata is information about the business, it helps defining and charaterising the various elements that are specific to the considered field or the domain of activity. We will find in business metadata information and details about concepts, business processes, entities, actors, etc. Everything that is tightly linked to the specificity of the considered business environment will be in the business metadata.
Technical metadata describes elements that are more concrete, physical and that enables data valorisation within the dedicated business. Databases servers, data platforms, network environments, physical assets or more generally technical elements can be found in technical metadata. Structure of data, relationships between tables or concepts, or any other technical detail are elements of technical metadata.
Operational metadata captures data about data in operations, giving a live description of living data assets. We can expect to find information in operational metadata about scheduled processes, execution logs, data storage configuration, processing resources, or the dedicated Data Lineages. All these detailed information gives context, and concrete operational data about the various assets described in the metadata.

We can also have a look at metadata by the lense of their structure and their type of content, grouping them into some dedicated categories. Defining these categories and understanding their origin and reason can help defining objectives of Metadata Management within an organization. Three main categories can be found in most metadata use cases: Descriptive, Structural and Administrative.
Descriptive metadata is a category of information that describes a resource, an element or an asset. It is really useful to identify elements in a given context, to perform search & discovery queries on these assets, and it gives as much descriptive information as we could find in any standard administrative form. Descriptions, tags, definitions, and names are examples of elements that constitute descriptive metadata.
Structural metadata are information that are more related to the structure of the considered described assets, and their potential relationships with other data. We can find in structural metadata elements that describe the composition of data, their inner structure and their hosting environments. Type of data, database schema, interactions and relationships diagrams are information we can find in structural metadata.
Administrative metadata is an other type of metadata that focuses on information used to manage data during their complete lifecycle. Creation date, version numbers, and last update status are administrative metadata essential for data handling, and Data Management strategies and information coherence. Managing data is an easier task with available and relevant administrative metadata.

3. Strategy
When it comes to Metadata Management strategy, there are a few things to have in mind. Like any other strategy, we expect to find elements about Goals & Planning, as well as alignment with business objectives. We should have information about the various actors, the concerned and dedicated Stakeholders & Users. The strategy of Metadata Management should also focus on specific Data sources & Databases, that contain the relevant information to extract and catalog. We also want to see the potential Architecture of the solution that should help reaching the defined goals. Finally, we definitely expect to find in a Metadata strategy the Implementation plan for development.
Defining Goals & Planning in a Metadata strategy means to ensure a roadmap is defined and clear for every actor in the said strategy. These same actors should contribute and collaborate to define short and long-term goals related to Metadata Management. This could be a set amount or percentage of data assets registered in the Data Catalog, or to animate and maintain an active community around Metadata Management. Planning of the detailed steps to reach these goals is important to convince and bring the key stakeholders in the process.
Talking about Stakeholders and Users, the important thing to understand is that they can either have a business or a technical background. Knowing this, it is important and even essential to adapt the vocabulary, the level of abstraction and the amount of details regarding the audience you have in front of you. Business stakeholders will be more interested in the value the solution brings, the ability to use it efficiently to enforce their business activities. On the other hand, technical users will be more demanding of technical and detailed information.

Data sources & Databases are data and information that reside at the center of a Metadata Management strategy. Designing a strategy around Metadata Management often includes the selection of a dedicated set of information sources, should they be internal databases, systems or external data sources and providers. It is very important to identify beforehand a list of data sources that are concerned for a first step into a Data Catalog alimentation process, and extend its perimeter after having proved the value of such a solution on a small perimeter.
The Architecture of the chosen Metadata Management solution is also critical, as it can change data alimentation and update patterns, as well as search, discovery and query capabilities of the complete system. Various types of architectures exist, but the most common ones are the centralized and the distributed architectures. There are specificities for each architecture, with some advantages and drawbacks related to the availability, to the quality of querying results or even to the maintenance of such systems.
Finally, an Implementation plan might be a critical element to take into account when designing a Metadata strategy, as systems do not appear and start working with some kind of magic. Implementing a Metadata Management solution takes time, planning, validation steps, integration and priorisation processes, etc. Documenting and detailing the implementation phases and the various elements that lead to the final solution is essential, for the technical teams to put in service the Metadata Management system and guarantee its expected behaviour.
4. Architecture
A Metadata Management solution is always built following a specific architecture. Depending on when you design your solution yourself with proprietary code components and infrastructure, or whether you use Components Off The Shelf (COTS) from the market, the solution will be built upon a dedicated configuration. The two main solutions we can encounter for a Metadata solution are Centralized or Distributed.
When we consider a Metadata Management system, we usually see three main components in the solution: the Query Interface, the Metadata Storage, and the Information Threads. The Query Interface is the user-interface through which users request or query metadata in the system. The Metadata Storage is the storage system that holds data, and transfer them to the Query Interface when data is asked by the user. Finally, the Information Threads are the technical pipelines through which data transit between source systems and the Metadata Storage. Depending on the architecture of the Metadata Management solution, some components exist or not and have adjusted roles.
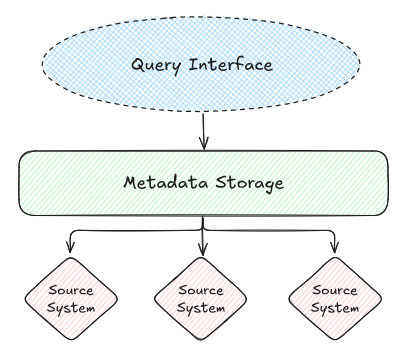
A Centralized architecture for a Metadata Management system is an architecture in which the Metadata Storage has an essential and critical role. On one hand, it retrieves internally the relevant information it already possesses about the source systems. On the other hand it responds to the Query Interface to expose only relevant data to the user, corresponding to its query or search request. Acting as a database, the Metadata Storage does not depend on the availability of the source systems to answer the input queries, but can be desynchronised from the reality of the source systems. Note that the process of updating data retrieved from the source systems in the Metadata Storage can totally be automated and scheduled, in an asynchronous and independant process from the query answering process.
A Distributed architecture on the contrary really focuses on the reality and coherence of the answer given by the Query Interface to the user. To do so, when a request is performed by the user, the Query Interface directly transfers the request to the source systems to retrieve fresh data through Information Threads, before formatting the result and answering. The Metadata Storage sometimes does not even exist in this configuration, because the query is distributed on the underlying source systems. However, the answers in this type of architecture can be slower, as more actors interact in the process to provide an answer to some query.
Hybrid architectures can also be seen, usually to benefit from the advantages of both centralized and distributed architectures. Having a Metadata Storage helps having a persistence layer for metadata that are retrieved through the Information Threads from the source systems. But requests performed by the user and the Query Interface can ask the Metatadata Storage component to perform two tasks: retrieving more recent data on the considered data sources in the query, and updating its internal repository/database. The Metadata Storage then aggregates and formats all these data, before transfering them to the Query Interface and answering the user request. In this context, retrieved data can be more relevant and answer delay is not that long because it still focuses on the Metadata Storage capabilities and available data.

Before implementing a Metadata Management solution, it can be interesting to design a Meta-model to understand and specify what needs to be managed and catalogued as metadata. A meta-model is very useful to confirm the alignment of the solution vision with existing business requirements. This also helps defining the potential future content of the designed Metadata system. The main principles of a meta-model focus on entities and concepts, and relationships between these concepts. It is just like a standard data model, with an accent on metadata. We can design two types of meta-models for Metadata Management: High-level conceptual and Low-level detailed meta-models.
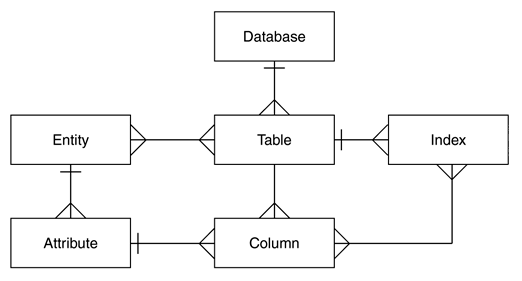
High-level conceptual meta-models capture the main concepts in the planned Metadata system. These concepts can be modeled as entities, that represent the various characteristics, contents and behaviours of such concepts that represent data. Entities should model concepts that can be identified or tied to real metadata, as these serve as guiding lights for implementation. Entities interact with each others through relationships or links more generally. These links permit to understand how the various data, elements and concepts are tied together.
Low-level detailed meta-models on the contrary are based on thin levels of details to describe the various entities attributes, data content and relationships specifities. You can expect to find concrete details of implementation and real content in terms of data in a detailed meta-model, that give substance and reality to the considered metadata. These low-level meta-models are close to ground reality and can really help in specific implementation phases or during debugging steps of metadata issues. Regularly checking the alignment between meta-models and the reality implemented in Metadata Management solutions can be a complex but structuring task to ensure the pertinence of metadata.
5. Data Catalog
Metadata Management solutions can sometimes take the form of Data Catalogs, or Data Catalog can be a component among others within the Metadata Management solutions. When we talk about the generic concept of Data Catalog, we expect to find in the solution some dedicated set of features such as discovering the business vocabulary and concepts, exploring the available Data Dictionaries or even analyzing the Data Lineage, to cite the most important ones.
Business Glossary is a central pillar within Data Catalogs, as this represents some kind of reference for the whole perimeter of data assets contained within the catalog. Data assets, transformations, Data Lineage and usage of data are always related to a specific business area, and Business Glossaries help defining these by defining Business Concepts, Definitions & Relationships and Roles & Processess.
Defining Business Concepts is crucial for the right use of the Data Catalog by the end users. Indeed, having a clear vision about the business relative to the organization, and a global organization of concepts terms is essential to link the right assets within the Data Catalog to their corresponding elements in the business world. It is also very important to have a representative view of the business core elements.
Users can find Definitions & Relationships in the Data Catalog, to gain an even better understanding of the business world they interact with through their journey in the Data Catalog. Defining terms and concepts, giving precise and unique definitions and explaining relationships between various terms is a central thing to take care of, the ensure the value of the Data Catalog and its use by the various stakeholders.
We also expect to find and understand some details about the Roles & Processess that are specific to the corresponding business area. Understanding the different business actors and their associated roles, the processes they use on a daily basis, and how they interact within their respective area of business is elemental to globally understand the business concerned and the perimeter of the company Data Catalog.
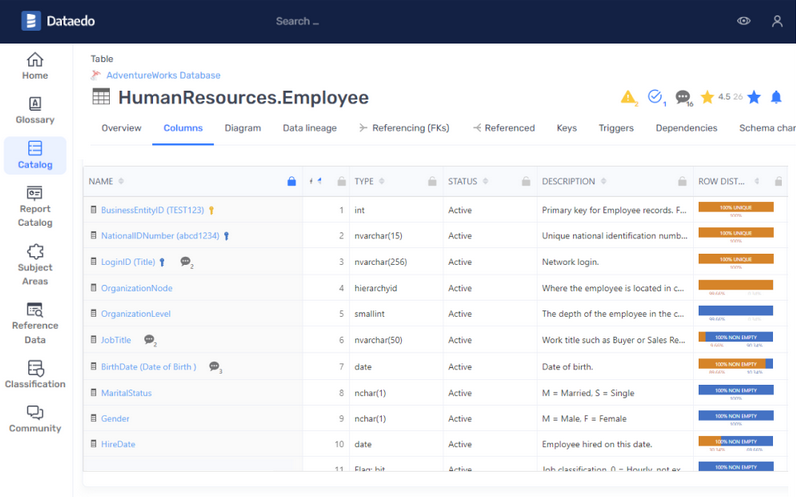
We expect to find Data Dictionaries within a Data Catalog, as these are the elemental bricks of this kind of solutions. Data assets are described by their content and structure, they can be all sorts of components within a data valorisation chain, such as projects, datasets, processing steps, dashboards, algorithms, etc. Data Dictionaries document Content & Structure, Logical Data Models, and Physical Data Models.
The Content & Structure of data assets are the core element of Data Dictionaries in a Data Catalog, as these are the concrete description of the said assets. Metadata such as Data Dictionaries describe the content of data captured in the Data Catalog, but also the structure of the various elements that compose data. Providing as much information as possible on data assets is important to inform users. The main strength of a Data Catalog is to act like a catalog in its purest form, and to provide a platform to consult and have information about data assets.
Logical Data Models are found through the various definitions of datasets associated with business concepts in the Data Catalog. Understanding which table is linked to a specific term, how various datasets interact together, or how a global data model is implemented through a logic or conceptual data model is important for users to be sure they use the right asset for the right use case. Data in the Data Catalog, especially Data Dictionaries, should be considered a real single source of truth regarding data assets.
Physical Data Models can also be exposed within Data Dictionaries and documentation elements, as these are the ground truth representation of the conceptual assets we can find in a Data Catalog. Being able to find the corresponding table in the dedicated database of the specific physical server or instance, thanks to the Data Catalog, is very important for users to have the accomplishment feeling of finding a specific data asset, and having an up-to-date knowledge about data it concerns.
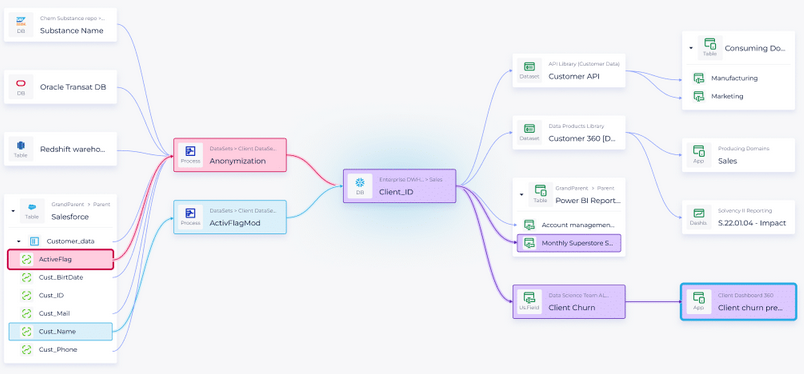
Last but not least, visualising the Data Lineage of a given project, a processing chain or more generally of a business context is mandatory to have a valuable Data Catalog solution. The Data Lineage is a visual solution that represents the flow of data throughout the various elements that handle them. Often represented as a graph, the Data Lineage permits to easily and visually understand where the data came from, through which components or processing chains it went, and where it landed for final use by end users, customers or stakeholders. Data Lineage features usually expose Processing & Transformations, Movements & Data Sharing and Impact Analysis.
The Processing & Transformations steps that build up a complete data valorisation chain are the essential part of a Data Lineage. Data is retrieved from various Data Dictionaries, to be processed and transformed by some processes, data projects or actors, to create some new data dictionaries. The main goal of a Data Lineage is to track down and register all these operations to have the ability to understand them globally.
Visualize Movements & Data Sharing can quickly become difficult in very large and complex data systems. Having a Data Lineage at hand is a big help to have a quick overview of data usage, where and how data moves between actors and systems, and also to understand the various patterns of data sharing that have been implemented within an organization.
Data Lineage is also very useful and powerful to perform Impact Analysis. By having direct access to the complete graph of projects and data assets dependencies, users can visually perform an analysis of impact regarding some projects criticality or asset importance. Some Data Catalogs even permit to have this kind of analysis feature directly in their visual interface by putting some links in evidence.
6. Governance
A Metadata Management program can only be efficient when it is leaded with the right governance. Governance of data, processes and practices behind Metadata Management are powerful helpers to reach success. Having a strong governance in Metadata Management means having efficient and organized processes, rigorous documentation activities, and strong standards and guidelines.
Alimentation Processes to insert data in a Data Catalog, or more generally of a Metadata Management system, are key to the solution lifecycle. The organization should be able to capitalize on data through controlled and mastered processes. These processes are at the core of data movement, data flows, definitions and interfaces with data uses, in the form of Data Integration or Alimentation campaigns.
Data Integration patterns and solutions take a very large part of data movements into an organization. We often hear about ETL (Extract, Transform & Load) or ELT processes, and data sources software connectors as Data Integration solutions. These are powerful means to insert data and metadata in a Data Catalog, but these are also complex components to document and control within a software architecture. Having well defined and documented processes regarding Data Governance, components interactions and interfaces with the Metadata Management solution is critical.
Alimentation campaigns are usually run when very specific data and metadata must be added by a few set of people that have the knowledge. This sometimes can be the case for very complex business vocabulary and concepts, or for a very specific set of data dictionaries that are hardly manageable in other ways. Manual ingestion processes must then be controlled and validated to ensure the Metadata Management system still stays manageable and accessible for users.
It is also very important to have Documentation associated with Metadata Management solutions. There are a lot of elements, context, models and meta-models going through a Metadata Management system. All these elements must be documented for a better use by actors and end users. For instance, they can expect to find documentation about Data & Metadata Models, Reference Documents or Data Assessments.
Data & Metadata Models are the central point of focus when we talk about a Metadata Management solution documentation. Any actors interacting with the solution expect to find some help, keys or information to understand the content of metadata, the model data has been organized with, some kind of meta-model to have an overview of the Data Catalog content, etc. Documenting these models is extremely important for maintenance, evolution and users accessibility purposes.
Reference Documents should also support managed metadata, for a better use and exploitation of said data. Being able to find in the Metadata Management solution (or accompanying tools) the meta-model that has been used to model the organization data assets, to understand the various elements, or to understand the business vocabulary with business context elements is very important. These documents will be even more helpful for actors and end users that expect to use the solution, but also to support the team responsible of its governance.
Data Assessments are very powerful tools and methodologies to assess, track down and register data usage within an organization. It helps linking a planned use of data (in the form of a dashboard, an application, a data sharing pattern, etc.) to the corresponding elements, assets and actors within or outside an organization. It is simply essential to have data usage validation crosspoints, and an efficient end-to-end traceability of data through their various mediums of use.

Standards & Guidelines are also a set of pillars that gives Data Management some references and expectations in terms of professional practices. There are a large number of good practices we can find regarding Metadata Management, but a few that can prove useful and efficient are centered around the notions of Nomenclature & Patterns and Data Quality.
In order to have organized and professionalized practices around data projects, setting up a list of Nomenclature & Patterns rules to follow during the development are a quick way to standardize Data Management. Having naming rules for projects, for data assets, following dedicated transformation patterns and models are efficient methods to have uniform data projects and practices. Besides, this will help a lot in reducing efforts to control Data Governance and Data Quality matters later on.

Talking about Data Quality, the most powerful and impactful way to have governed and professional data practices in projects is to set up Data Quality metrics, and ways to measure/analyze them automatically and regularly. This can be done by setting up a set of automated processes on the side to track down and evaluate measurements, or to use COTS with integrated Data Quality measurement and analysis features. Measuring, monitoring and driving the development of data projects throughout Data Quality metrics is a powerful driver for metadata.
7. Metrics
Finally, when we talk about a Metadata Management system, of course there is the strategy on how to handle this program, there is the architecture of the chosen solution, there is a governance to put in place to ensure its success, etc. But the most important piece of Metadata Management program should be the set of metrics that we consider to ensure the efficiency of the resulting organization.
Chosing metrics for a Metadata Management system can be quite difficult, but it should always rely on the business goals you are trying to solve under the hood. Do you need an easist way the access, search and discovery data within your organization ? Do you want to ensure the complete coverage of functional domains by your Data Governance actors ? Do you want to have an easy way to synthesis the quality of your internal data initiatives ? … All these questions will lead you to put more efforts and priority on some metrics rather than the others.

One of the most essential metric to take into account for a Metadata Management system is its Availability. Users, when they are given to such capabilities through a Data Catalog solution for example, expect the system to be available and ready to use at any time. Thus, updates on data contained in such a system should not block concurrent users, and the data platform hosting the solution should be resilient enough to ensure the service running conditions are almost 24/7.
In terms of Representation, by essence and definition of a complete Data Catalog, your Metadata Management must provide some kind of diversity. Just as organizations are, the content of your metadata must represent the variety of departments, business lines and activities that occur inside your environment. It is important to have clear, complete and accurate metadata about your concerned global environment.
By definition, a Data Catalog must make its dad-to-day objective to approach perfect Completeness. Of course, this is a very complex goal, even almost impossible given the high variability and evolution rate of the activies and environments within an organization. However, ensuring data are accurate about people, entities, concepts is crucial for the efficience of the Data Catalog. Making sure missing fields or incomplete information are identified, and covered by a short/mid/long-term process for being completed, ensures the system will keep its added value.
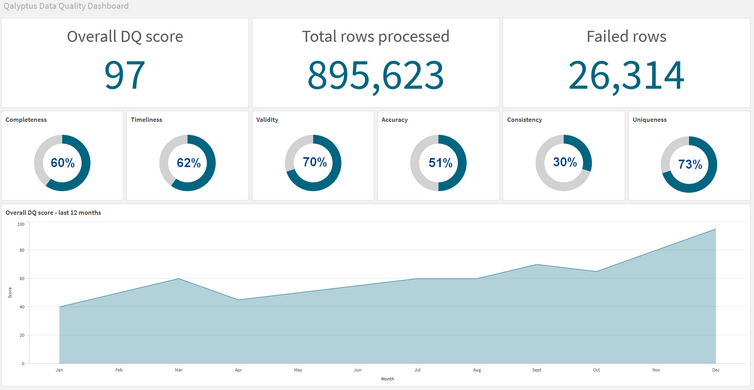
Therefore, we cannot talk about the Metadata Management system completeness without having a word on data Quality. The power of such systems resides also in the ability to tag/flag elements of metadata with their corresponding level of Data Quality. Approving elements in a Data Catalog that are marked with a sufficient level of quality and trust can be critical to users, as a mission of providing a central metadata repository and search/discovery capabilities.
Having a Metadata Management system or interface is great, but being able to control the Activity of your system is even better. Making sure your Data Catalog is used, by the right people, at the right frequency, gives credit to your Metadata Management solution. It can become even more interesting later on to track down the frequency of metadata updates inside the Data Catalog, and to also visualize the relevant functional domains that are the most or least active, those that really need data updates and a documentation activity increase.
The Usage metric is tightly linked to the Activity of the Data Catalog, but it can be seen as a philosophical way of ensuring data is used by the right people for the right things and the right reasons. Data Lineage capabilities are a powerful solution to measure the Usage metric and ensure there is no compromising use of data within a dedicated perimeter or environment. It is valuable as well to have an idea of whether catalogued metadata on given domains is exploited or if it remains silent.

Making sure your Metadata Management systems and solutions are of perfect Compliance regarding laws, rules and data regulations standards should be one of the daily priority of a Data Governance team. There exists a lot of standards, regulation entities, laws depending on countries and data storage locations… This can become an easily overwhelming mission for relevant profiles, but making sure the considered systems and solutions are Compliant added even more credibility to the team managing these Metadata solutions.
Last but not least, evaluating the Maturity of a Metadata Management solution, an environment or more generally an organization is very difficult. This can be seen as a complex combination of all the previous metrics discussed in here, in a way that exposes the complete mastery of an organization’s own collected and managed metadata. There exists a few methodologies and models that help evaluating an organization’s maturity level, ranging from the “unaware” level to the “strategic” level, positionning the company depending of its proficiency in the domain.
8. Conclusion
Metadata Management is a very complete and complex field of Data Strategy, that revolves around the management of metadata to increase the value of data. Managing metadata means understanding what are metadata, how they can be used to create value, and how to integrate architecture patterns and governance methodologies to have a coherent operating model. Data Catalogs are powerful tools to help managing metadata, and providing actors a consolidated interface to discover, search and analyze the impact of data assets in an organization.
Implementing a Metadata Management program is not easy, it takes time, planning and strategy, to make sure the most relevant steps are mastered, but also aligned with business objectives. Integrating stakeholders and making sure the metadata lifecycle is well managed is a big challenge, but definitely worth the value it helps generate when the discipline is executed in a professional context.