Data Platforms Architecture
Data Platforms Architecture is the core technical enabler for Big Data Analytics and more generally Data Management activities.
1. Introduction
Data Analytics, Data Science, Artificial Intelligence… so many buzzwords for a single technical field revolving around Data Management activities. But implementing all those cutting-edge and trending systems are usually only possible with the relevant corresponding data platform. The underlying technologies, network environments and technical capabilities are the key to fully exploit the potential of these data solutions.
Nowadays, when we talk about data platforms, we often consider three main configurations of data infrastructures: Data Warehouses (and by extension Data Marts), Data Lakes, and Data Lakehouses. These are three different possibilities, with their technical and physical specifities, that enable large scale and efficient data processing to extract value from data. Providing insights to end-users based on data solutions is essential in Data Analytics activities, and data platforms architectures are often the first step to consider before deploying wide range solutions.
2. Data Warehouses
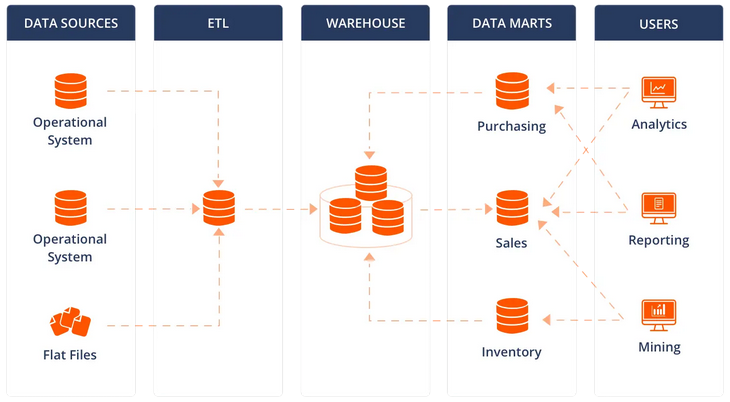
Data Warehouses are essentially transactional systems optimized for data analytics and reporting tasks. They are mainly composed of relational databases, benefitting the ability to model concepts, entities and relationships between elements. They usually act as central repositories of data, also known as single source of truth within an organization.
This kind of data platform architecture is by nature very efficient, as it is strategically organized for a dedicated perimeter, with key data easily accessible. Data tables and attributes are normalized, values are standardized and cleaned beforehand, all of this leading to a qualitative repository of integrated data. However, this type of solution can quickly become costly, because of the underlying powerful mechanisms.
Data Warehouses and relational databases in general guarantee what we call the ACID principles in transactions: Atomicity, Consistency, Isolation and Durability. A transaction is a set of events, or mutations, that happens to data when a modification is performed on data. Atomicity guarantees that a transaction applies completely or not at all, not partially. Consistency means data will always be left in an valid state regarding constraints. Isolation ensures data will always be in a coherent state, whatever the potential concurrency of access. Finally, durable transactions ensure their results are saved and remain still, even in case of system failure.
This type of data platform architecture usually captures data over time, to build a complete data history. These configurations are very interesting to perform data analytics and business intelligence use cases on large volumes of organized data. Data is often split and specialized regarding functional domains (engineering, finance, human resources, etc.), and we often talk about Data Marts when we consider these specific subsets of data.
Finally, Data Warehouses are usually powerful in terms of Data Governance, as perimeters and access rights on data can be efficiently defined and controled thanks to relational databases management systems (RDBMS). Tables and views can be organized regarding different concepts, and access to their data can be controled with users access permissions.
3. Data Lakes
Data Lakes are more complete, more generic but less optimized data platforms, designed for Big Data analytics, data mining and Machine Learning. This kind of architecture is usually considered as a very large storage system, where data sources are ingested and stored “as in”, whatever their format or size. It can contain structured, semi-structured and unstructured data seemlessly, and is a considered as a central platform for various data consumption uses.
The generic factor of this type of data platform architecture makes it poorly efficient, as it must adapt to very heterogeneous types of data, formats, volumes, etc. However, this is also what makes its biggest strength: the ability to handle a large variety of data sources, and to keep all these information stored safely, with integrity whatever their format.
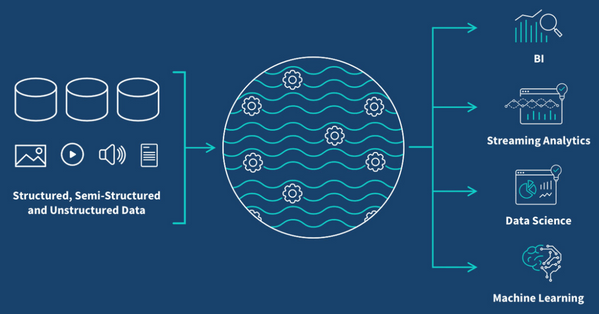
A very interesting aspect of Data Lakes architectures is the possibility to provide benchmarking and exploration sandbox environments for data analysis in general. More than a very large scale and generic storage system, this data platform architecture solution also provides means for technical users to access raw data contained in the platform, and to perform analysis and exploration tasks. Prototyping solutions on a Data Lake architecture permits to build better fit data products later on.
Data Lakes are usually implemented thanks to cloud technologies, permitting a very efficient scale-out factor. Adding more resources or physical servers is possible on demand, when this is required. This is a very agile model, that resonates on the price of this data architecture, making it very cost-efficient contrary to constrained and expensive Data Warehouses solutions.
However, a large drawback of this kind of data platform architecture is the total lack of Data Governance capabilities. Indeed, raw unstructured data, with no data quality rules or standards, potential duplicates and high variability/volatility poses great challenges to apply a Data Governance strategy on this kind of platform.
4. Data Lakehouses
Data Lakehouses are the best of both worlds, combining strengths from Data Warehouses and Data Lakes. While using the core concepts of Data Lakes to store data efficiently and being agnostic to their format, this architecture benefits interesting features from Data Warehouses such as ACID transactions, being compatible with streaming data, data historisation and deletion, being able to request data and use comprehensible data schemas, etc.
A very powerful feature of Data Lakehouses is the addition of a dedicated Metadata Management System, also called a Data Catalog. With the help of a centralised repository of information, data can be referenced, combined and enriched with environment information, bringing even more values to the eventual resulting analysis. It is also a very strong asset for data end-to-end traceability, thanks to Data Catalogs capabilities such as Data Lineage, Data Governance and Data Quality checkpoints.
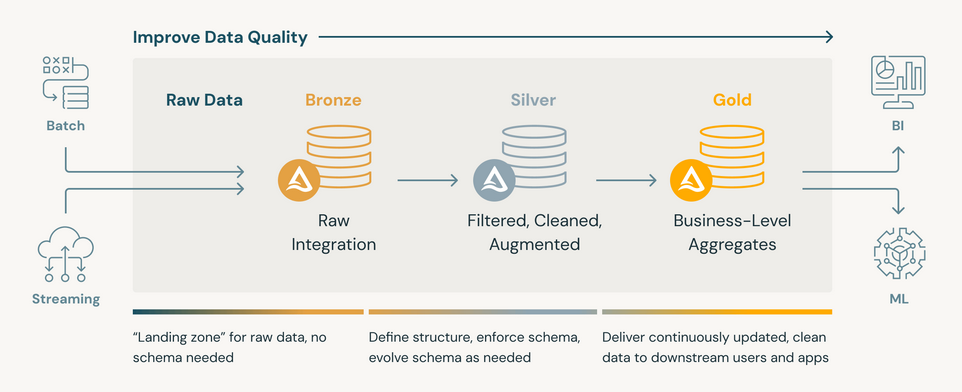
A strong architecture principle put in place in Data Lakehouses is the Medallion Architecture. This models consists in defining three levels of data (Bronze for raw data, Silver for transformed data and Gold for enriched data) throughout the platform, making possible a thin data access control depending on the considered uses and governance models. These various levels are different sets of data with different quality levels, ensuring users to retrieve data with the right standards.
Data Lakehouses are very powerful and complete Data Platforms Architecture, providing interesting Data Governance elements such as data definition, access controls and Data Quality norms, giving a real trust into data stored and used. They also proving important features related to Data Quality and data lifecycle management like historisation, deletion, traceabillity, etc. Finally, they combine strengths of cost-efficient storage, reliable data processings transactions and governance-compatible execution models to become the next step after Data Warehouses/Data Lakes standard platforms lately.
5. Opening on Data Mesh Architecture
Even though Data Lakehouses are the preferred and optimised data platforms architecture to go with nowdays, a new kind of data architecture is gaining more and more interest lately : the Data Mesh.
Data Mesh is relatively new data architecture proposed, focusing on ownership, decentralization and governance principles. This kind of solution should permit to scale a data architecture across an organization where business and technology both evolves. Data Mesh revolves around the idea of data products that are organized into domains, with 4 principles that are technology-agnostic: data ownership by domains, data as a product, data available everywhere self-served and data governed where it is.
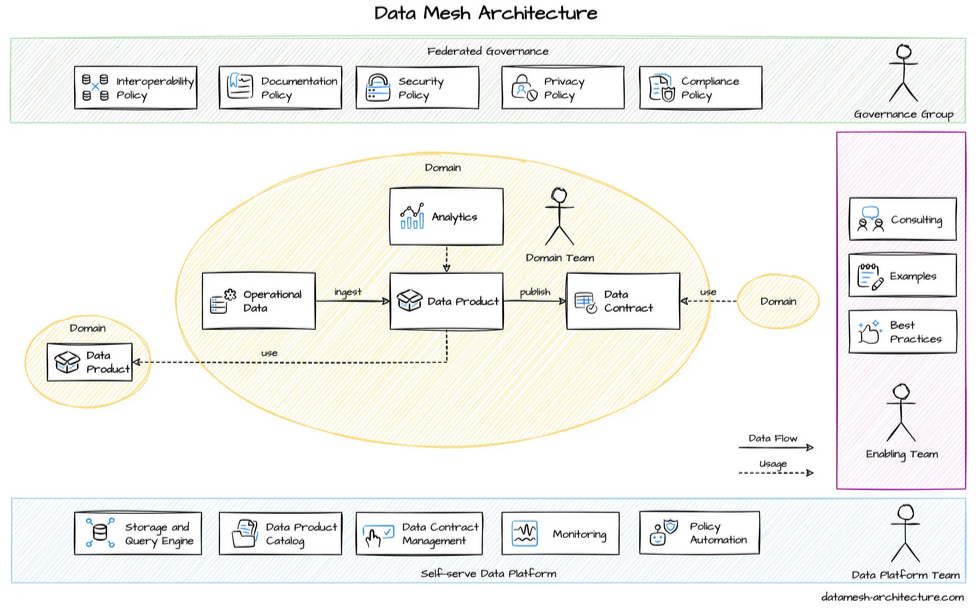
Data Governance models are meant to evolve and adapt to this new concept and data architecture, but this should solve many problematics that are encountered with modern data architectures, such as ownership and data control, data sharing principles and quick local evolutions. Everything is interconnected just like a mesh, with data products being nodes connecting domains. Data Mesh is really a new data architecture to keep an eye on in the next few years.